I’ve been writing quite a bit about CQS (or command and query separation) lately. In my last post on using events, I already hinted towards bringing in the R; command and query responsibility separation.
With CQS, commands can mutate data, while queries can only read that data. CQRS takes this one step further, and assigns commands and queries each a dedicated model; we now talk of a write side, and a read side.
I like Clemens Vasters definition best.
CQRS is a simple pattern that strictly segregates the responsibility of handling command input into an autonomous system from the responsibility of handling side-effect-free query/read access on the same system. Consequently, the decoupling allows for any number of homogeneous or heterogeneous query/read modules to be paired with a command processor. This principle presents a very suitable foundation for event sourcing, eventual-consistency state replication/fan-out and, thus, high-scale read access. In simple terms, you don’t service queries via the same module of a service that you process commands through. In REST terminology, GET requests wire up to a different thing from what PUT, POST, and DELETE requests wire up to.
A nice drawing also helps in understanding CQRS (from the CQRS journey material).
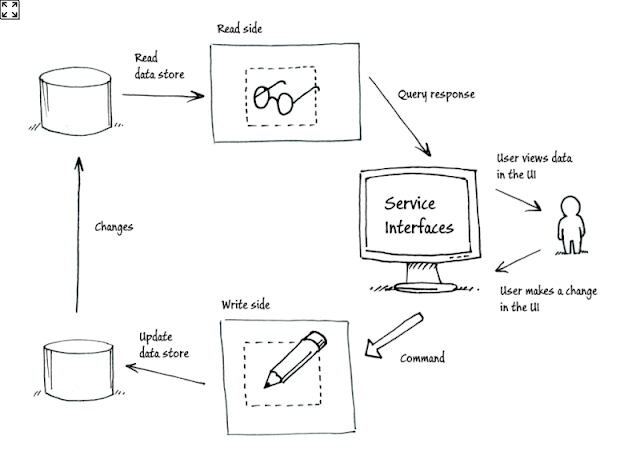
Although scalability seems to be one of the big selling points of CQRS, there are still some valid arguments applicable to my world; the strongest one being able to avoid the discrepancy which exists while you use the same model for reading and writing. I think everyone suffers from this one regularly. A popular and realistic example is this one; an ORM is used to map our domain model to a relational database, the tables are mapped very closely to the structure of the domain model. Not long after, it becomes evident that it’s impossible to write simple and performant queries targeting this datastructure. We could optimize for reads, but this would impact the complexity and performance of writing. With CQRS, reads and writes are segregated; we can now optimize both parts independently. And this doesn’t only result in being able to show a list faster on a user’s screen, but interesting things can also be done to empower reporting and data mining; think of how often using the same database for these tasks makes it hard and expensive to change things.
While I still have done very little with CQRS, I have been looking at more and more real world examples, trying to fill in the blanks. What always has been kind of vague to me, is how you go at storing your domain model, and your read models in practice. Here are a few possible techniques - these are some proven techniques, and partially my own presumptions (you hardly find any OSS brown field examples).
The compromise
CQRS doesn’t have to be an application-wide architecture necessarily; nothing stops you from introducing it gently, and just applying it to parts of your application where the added value is over-obvious. This could mean that you use a conventional architecture; a relational database with an ORM, or a document store, not distinguishing the write side from the read side. Yet for certain scenarios, you could introduce a specialized read or write side. For example; update the statistics read model on every relevant write, update a denormalized optimized read model for searches, etc..
NORM
While the relational paradigm definitely has its place, mapping your domain to the database can get complex, and require much maintenance. If you don’t expect of your write side to be queryable, you can take advantage of less cumbersome techniques such as a key value store to store your domain model. This does force you to completely separate reads from writes though.
Event Sourcing
When you look at most OSS CQRS implementations, Event Sourcing and CQRS go hand in hand. With Event Sourcing, you capture all application state changes as a sequence of events. I’m really fond of the theory behind this pattern, and I can imagine the added operational value of having a log of each change. Yet, I also think you could largely achieve the same result by enabling journaling and adding some interception. Storage wise, you store all the event streams in an event store, which is optimized for such a task. Your read side can again be whatever you fancy.
These three techniques aren’t mutually exclusive. There are a bunch of arguments to consider, and everything is highly dependent on your technical and operational requirements.
What is your experience with CQRS? Which techniques have you applied in practice?