Last week, I implemented an event sourced aggregate from scratch. There I learned, that there isn’t much to a naively implemented event sourced aggregate; it should be able to initialize itself from a stream of events, and it should be able to record all the events it raises.
public interface IEventSourcedAggregate : IAggregate {
void Initialize(EventStream eventStream);
EventStream RecordedEvents();
}
The question I want to answer today is: how do I persist those event sourced aggregates?
In traditional systems, aggregate persistence is not a trivial topic.
Especially relational databases have the reputation to make things hard
on us. Even though tools such as ORM’s have tried to help in making the
gap between the relational and object oriented model as small as
possible, there is still a lot of friction associated with the notorious
impedance mismatch.
The last two years I have done some work using one of the popular NoSQL
variants: a document store. In this paradigm, each aggregate
materializes into a single document. Structure, constraints and
referential integrity are not enforced by the database, but by code. The
advantage of relaxing consistency at the database, is that it makes it
easier to scale outside a single machine, and that developers feel more
empowered. Giving in on consistency guarantees is not acceptable for
each system though. Again, pick the right tool for the job.
What both paradigms have in common is that they both focus on structure
instead of behaviour.
Event sourced systems on the other hand, don’t care about the structure of an aggregate, but about the events that caused the aggregate to be in its current state. Only having to store events - which are represented as DTO’s - makes persistence and tooling much easier compared to traditional systems.
There are three things a minimalistic event store should be able to do:
- Store a new event stream
- Append to an existing event stream
- Retrieve an existing event stream
An interface for that could look like this.
public interface IEventStore {
void CreateOrAppend(Guid aggregateId, EventStream eventStream);
EventStream GetStream(Guid aggregateId);
}
Notice that there is no update or delete - events happen, we can’t jump in a time machine and alter the past. This allows us to get by with an append-only data model. Can you imagine how much easier to implement, optimize and distribute this must be compared to traditional models?
As an exercise, I took the interface I just defined and implemented a durable, non-transactional, non-scalable (up to 4294967295 streams), single-user event store that persists event streams in raw text files. Each record on disk represents a serialized event with a tiny bit of metadata.
public class FileEventStore : IEventStore {
private const string Dir = @"C:\EventStore";
public void CreateOrAppend(Guid aggregateId, EventStream eventStream) {
EnsureDirectoryExists();
var path = EventStoreFilePath.From(Dir, aggregateId).Value;
using (var stream = new FileStream(
path, FileMode.Append, FileAccess.Write, FileShare.None))
{
using (var streamWriter = new StreamWriter(stream))
{
streamWriter.AutoFlush = false;
foreach (var @event in eventStream)
streamWriter.WriteLine(
new Record(aggregateId, @event).Serialized());
}
}
}
public EventStream GetStream(Guid aggregateId) {
var path = EventStoreFilePath.From(Dir, aggregateId).Value;
if (!File.Exists(path))
return null;
var lines = File.ReadAllLines(path);
var events = lines
.Select(x => Record.Deserialize(x))
.Select(x => x.Event)
.ToList();
if (events.Any())
return new EventStream(events);
return null;
}
private void EnsureDirectoryExists()
{
if (!Directory.Exists(Dir))
Directory.CreateDirectory(Dir);
}
}
A long-ish test proves that I can create a stream, append to it and read it again without losing any data.
[TestMethod]
public void EventStoreCanCreateAppendAndRetrieveEventStreams()
{
var eventStore = new FileEventStore();
var aggregateId = Guid.NewGuid();
var account = new Account(aggregateId);
account.Deposit(new Amount(3000));
account.Withdraw(new Amount(400));
Assert.AreEqual(2, account.RecordedEvents().Count());
Assert.AreEqual(new Amount(2600), account.Amount);
eventStore.CreateOrAppend(aggregateId, account.RecordedEvents());
var eventStream = eventStore.GetStream(aggregateId);
Assert.AreEqual(2, eventStream.Count());
var anotherAccount = new Account(aggregateId);
anotherAccount.Initialize(eventStream);
Assert.AreEqual(new Amount(2600), anotherAccount.Amount);
anotherAccount.Withdraw(new Amount(200));
Assert.AreEqual(new Amount(2400), anotherAccount.Amount);
Assert.AreEqual(1, anotherAccount.RecordedEvents().Count());
eventStore.CreateOrAppend(aggregateId, anotherAccount.RecordedEvents());
var finalEventStream = eventStore.GetStream(aggregateId);
Assert.AreEqual(3, finalEventStream.Count());
}
This produced the following artifact on disk.
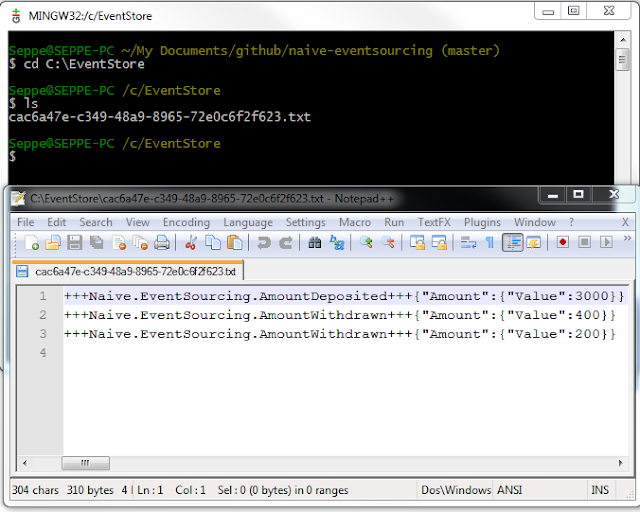
While this implementation is far from ideal - dangerous really, it does show that implementing a minimalistic event store is doable - especially if you can build on top of existing data stores.
Doable, but not trivial. Greg Young - having actually implemented an event store, on the CLR too - recently shared some invaluable insights into what it takes to build a real-world event store.
I have always said an event store is a fun project because you can go anywhere from an afternoon to years on an implementation.
I think there is a misunderstanding how people normally use an event stream for event sourcing. They read from it. Then they write to it. They expect optimistic concurrency from another thread having read from then written to the same stream. This is currently not handled. This could be handled as simply as checking the expected previous event but this wouldn’t work because the file could be scavenged in between. The way this is generally worked around is a monotonically increasing sequence that gets assigned to an event. This would be relatively trivial to add.
The next issue is that I can only read the stream from the beginning to the end or vice versa. If I have a stream with 20m records in it and I have read 14m of them and the power goes out; when I come back up I want to start from 14m (stream.Position = previous; is a Seek() and 14m can be very expensive if you happen to be working with files the OS has not cached for you). This is a hugely expensive operation to redo and the position I could have saved won’t help me as the file could get compacted in between. To allow arbitrary access to the stream is a bit more difficult. The naive way would be to use something like a sorted dictionary or dictionary of lists as an index but you will very quickly run out of memory. B+Trees/LSM are quite useful here.
Even with the current index (stream name to current position) there is a fairly large problem as it gets large. With 5m+ streams you will start seeing large pauses from the serializing out the dictionary. At around 50m your process will blow up due to 1gb object size limit in CLR
Similar to the index issue is that with a dictionary of all keys being stored in memory and taking large numbers of writes per second it is quite likely you will run out of memory if people are using small streams (say I have 10000 sensors and I do a stream every 5 seconds for their data to partition). Performance will also drastically decrease as you use more memory due to GC.
A more sinister problem is the scavenge / compaction. It stops the writer. When I have 100mb of events this may be a short pause. When I have 50gb of events this pause may very well turn into minutes.There is also the problem of needing N * N/? disk space in order to do a scavenge (you need both files on disk). With write speeds of 10MB/second it obviously wouldn’t take long to make these kinds of huge files especially in a day where we consider a few TB to be small. The general way of handling this is the file gets broken into chunks then each chunk can be scavenged independently (while still allowing reads off it). Chunks can for instance be combined as well as they get smaller (or empty).
Another point to bring up is someone wanting to write N events together in a transactional fashion to a stream. This sounds like a trivial addition but its less than trivial to implement (especially with some of the other things discussed here). As was mentioned in a previous thread a transaction starts by definition when there is more than one thing to do.
There are decades worth of previous art in this space. It might be worth some time looking through it. LSM trees are a good starting point as is some of the older material on various ways of implementing transaction logs.
Playing with Greg’s event store is something that has been on my list for a long time.
Next week: but how do we query our aggregates now?