In my first two posts on event sourcing, I implemented an event sourced aggregate from scratch. After being able to have an aggregate record and play events, I looked at persisting them in an event store. Logically, the next question is: how do I query my aggregates, how do I get my state out?
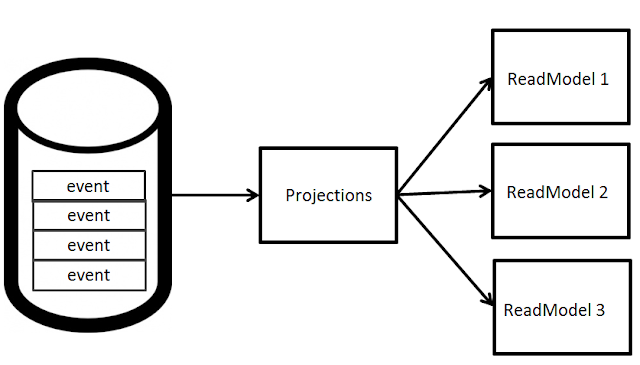
In traditional systems, write and read models are not separated, they are one and the same. Event sourced systems on the other hand have a write model - event streams, and a separate read model. The read model is built from events committed to the write model; events are projected into one or more read models.
An interface for a projection could look like this.
public interface IProjection {
void Handle(EventStream eventStream);
}
A projection takes in an event stream, and projects it to some read model.
A read model can be anything; a cache, a document store, a key value store, a relational database, a file, or even some evil global state.
public class EvilStatisticsReadModel {
public static int WithdrawalAmountExceededCount { get; set; }
public static int AmountDepositedCount { get; set; }
}
In this model, we want to maintain statistics of events that happened. For that to happen, we need to define a projection of our event stream.
public class ProjectionsToEvilStaticsReadModel : IProjection {
public void Handle(EventStream eventStream) {
foreach (var @event in eventStream)
When((dynamic)@event);
}
public void When(WithdrawalAmountExceeded @event) {
EvilStatisticsReadModel.WithdrawalAmountExceededCount++;
}
public void When(AmountDeposited @event) {
EvilStatisticsReadModel.AmountDepositedCount++;
}
}
If we now let this projection handle an event stream, our read model will be kept up-to-date.
[TestMethod]
public void ReadModelIsKeptUpToDateWhileProjectingTheEventStream() {
var events = new List<IEvent>() {
new WithdrawalAmountExceeded(new Amount(3000)),
new AmountDeposited(new Amount(300)),
new AmountDeposited(new Amount(500)),
new AmountWithdrawn(new Amount(100))
};
var stream = new EventStream(events);
new ProjectionsToEvilStaticsReadModel().Handle(stream);
Assert.AreEqual(1, EvilStatisticsReadModel.WithdrawalAmountExceededCount);
Assert.AreEqual(2, EvilStatisticsReadModel.AmountDepositedCount);
}
One could argue that all of this is too much - not worth the effort. Where you first just persisted the structure of an aggregate, and could query that same structure, you now first have to persist events for then to write projections that maintain separate read models that can be queried.
You have to look beyond that though. Those that have done any serious work on a traditional stack have felt the pain of migrations, complex queries that take up three pages, obscure stored procedures that run for hours, optimizing while having to consider a handful of different use cases, finding the balance between write- and read performance, database servers that can’t handle the load on special events, expensive licenses and so on. While these first few concerns are mostly technical, personally I’m often overwhelmed by how much concepts these designs force you to keep in your head all at once.
Separating reads from writes using event sourcing might bring some relief. Reducing cognitive overload by separating responsibilities into smaller, more granular bits might be the only argument you need. However, there’s a lot more. Running an event store should be low-maintenance; it’s an append-only data model storing simple serialized DTO’s with some meta data - forget about big migrations (not completely though), schemas, indexes and so on. Even if you project into a relational database, being able to re-run projections should make migration scripts and versioning avoidable. An event can be projected into multiple read models, allowing you to optimize per use case, without having to take other use cases into account. Since it should be easy to rebuild read models, they can be stored in cheap and volatile storage - think key-value store, in-memory and so on, allowing for crazy fast reads.
Letting go of the single-model dogma seems to enable so much more, giving you a whole new set of possibilities. Another extremely useful use case that suddenly becomes a lot easier to support is business intelligence; when business experts think of new ways to look at the past, you just create a new projection and project events from day one. Getting statistics of how your users are using your system doesn’t sound that hard now, does it?
One of the obvious drawbacks next to writing a bit more, boring code is that storage costs will increase - you are now persisting the same data in multiple representations. But storage is cheap, right? Maybe money isn’t an issue, but what about performance? It’s slower to do three writes instead of one, right? For a lot of scenarios this won’t be much of an issue, but if it is, there is a lot of room for optimiziations doing projections; parallelization, eventual consistency and so on.
Next week: event source all the things?